常春岛资源网 Design By www.syssdc.com
一:网页更新
我们知道,一般网页中的信息是不断翻新的,这也要求我们定期的去抓这些新信息,但是这个“定期”该怎么理解,也就是多长时间需要抓一次该页面,其实这个定期也就是页面缓存时间,在页面的缓存时间内我们再次抓取该网页是没有必要的,反而给人家服务器造成压力。
就比如说我要抓取博客园首页,首先清空页面缓存,

从Last-Modified到Expires,我们可以看到,博客园的缓存时间是2分钟,而且我还能看到当前的服务器时间Date,如果我再次
刷新页面的话,这里的Date将会变成下图中 If-Modified-Since,然后发送给服务器,判断浏览器的缓存有没有过期?

最后服务器发现If-Modified-Since >= Last-Modifined的时间,服务器也就返回304了,不过发现这cookie信息真是贼多啊 。

在实际开发中,如果在知道网站缓存策略的情况下,我们可以让爬虫2min爬一次就好了,当然这些都是可以由数据团队来配置维护了, 好了,下面我们用爬虫模拟一下。
复制代码 代码如下:
using System;
using System.Net;
namespace ConsoleApplication2
{
public class Program
{
static void Main(string[] args)
{
DateTime prevDateTime = DateTime.MinValue;
for (int i = 0; i < 10; i++)
{
try
{
var url = "http://cnblogs.com";
var request = (HttpWebRequest)HttpWebRequest.Create(url);
request.Method = "Head";
if (i > 0)
{
request.IfModifiedSince = prevDateTime;
}
request.Timeout = 3000;
var response = (HttpWebResponse)request.GetResponse();
var code = response.StatusCode;
//如果服务器返回状态是200,则认为网页已更新,记得当时的服务器时间
if (code == HttpStatusCode.OK)
{
prevDateTime = Convert.ToDateTime(response.Headers[HttpResponseHeader.Date]);
}
Console.WriteLine("当前服务器的状态码:{0}", code);
}
catch (WebException ex)
{
if (ex.Response != null)
{
var code = (ex.Response as HttpWebResponse).StatusCode;
Console.WriteLine("当前服务器的状态码:{0}", code);
}
}
}
}
}
}

二:网页编码的问题
有时候我们已经抓取到网页了,准备去解析的时候,tmd的全部是乱码,真是操蛋,比如下面这样,

或许我们依稀的记得在html的meta中有一个叫做charset的属性,里面记录的就是编码方式,还有一个要点就是response.CharacterSet这个属性中同样也记录了编码方式,下面我们再来试试看。
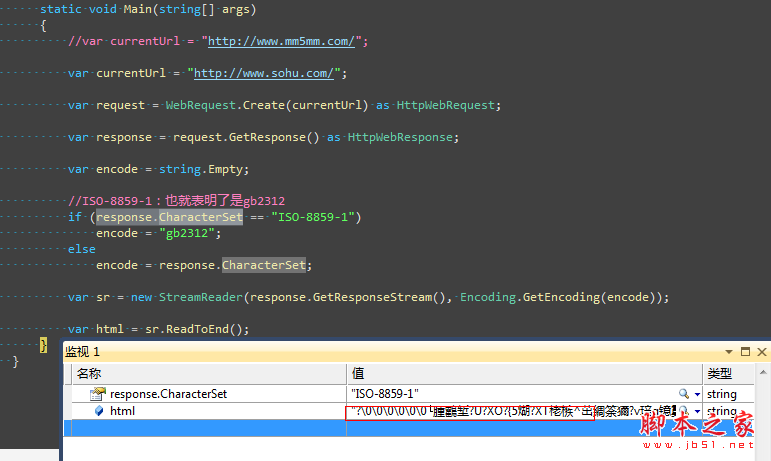
居然还是乱码,蛋疼了,这次需要到官网上面去看一看,到底http头信息里面都交互了些什么,凭什么浏览器能正常显示,爬虫爬过来的就不行。

查看了http头信息,终于我们知道了,浏览器说我可以解析gzip,deflate,sdch这三种压缩方式,服务器发送的是gzip压缩,到这里我们也应该知道了常用的web性能优化。
复制代码 代码如下:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading;
using HtmlAgilityPack;
using System.Text.RegularExpressions;
using System.Net;
using System.IO;
using System.IO.Compression;
namespace ConsoleApplication2
{
public class Program
{
static void Main(string[] args)
{
//var currentUrl = "http://www.mm5mm.com/";
var currentUrl = "http://www.sohu.com/";
var request = WebRequest.Create(currentUrl) as HttpWebRequest;
var response = request.GetResponse() as HttpWebResponse;
var encode = string.Empty;
if (response.CharacterSet == "ISO-8859-1")
encode = "gb2312";
else
encode = response.CharacterSet;
Stream stream;
if (response.ContentEncoding.ToLower() == "gzip")
{
stream = new GZipStream(response.GetResponseStream(), CompressionMode.Decompress);
}
else
{
stream = response.GetResponseStream();
}
var sr = new StreamReader(stream, Encoding.GetEncoding(encode));
var html = sr.ReadToEnd();
}
}
}

三:网页解析
既然经过千辛万苦拿到了网页,下一个就要解析了,当然正则匹配是个好方法,毕竟工作量还是比较大的,可能业界也比较推崇 HtmlAgilityPack这个解析工具,能够将Html解析成XML,然后可以用XPath去提取指定的内容,大大提高了开发速度,性能也不赖,毕竟Agility也就是敏捷的意思,关于XPath的内容,大家看懂W3CSchool的这两张图就OK了。

复制代码 代码如下:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading;
using HtmlAgilityPack;
using System.Text.RegularExpressions;
using System.Net;
using System.IO;
using System.IO.Compression;
namespace ConsoleApplication2
{
public class Program
{
static void Main(string[] args)
{
//var currentUrl = "http://www.mm5mm.com/";
var currentUrl = "http://www.sohu.com/";
var request = WebRequest.Create(currentUrl) as HttpWebRequest;
var response = request.GetResponse() as HttpWebResponse;
var encode = string.Empty;
if (response.CharacterSet == "ISO-8859-1")
encode = "gb2312";
else
encode = response.CharacterSet;
Stream stream;
if (response.ContentEncoding.ToLower() == "gzip")
{
stream = new GZipStream(response.GetResponseStream(), CompressionMode.Decompress);
}
else
{
stream = response.GetResponseStream();
}
var sr = new StreamReader(stream, Encoding.GetEncoding(encode));
var html = sr.ReadToEnd();
sr.Close();
HtmlDocument document = new HtmlDocument();
document.LoadHtml(html);
//提取title
var title = document.DocumentNode.SelectSingleNode("//title").InnerText;
//提取keywords
var keywords = document.DocumentNode.SelectSingleNode("//meta[@name='Keywords']").Attributes["content"].Value;
}
}
}

好了,打完收工,睡觉。。。
我们知道,一般网页中的信息是不断翻新的,这也要求我们定期的去抓这些新信息,但是这个“定期”该怎么理解,也就是多长时间需要抓一次该页面,其实这个定期也就是页面缓存时间,在页面的缓存时间内我们再次抓取该网页是没有必要的,反而给人家服务器造成压力。
就比如说我要抓取博客园首页,首先清空页面缓存,
从Last-Modified到Expires,我们可以看到,博客园的缓存时间是2分钟,而且我还能看到当前的服务器时间Date,如果我再次
刷新页面的话,这里的Date将会变成下图中 If-Modified-Since,然后发送给服务器,判断浏览器的缓存有没有过期?

最后服务器发现If-Modified-Since >= Last-Modifined的时间,服务器也就返回304了,不过发现这cookie信息真是贼多啊 。
在实际开发中,如果在知道网站缓存策略的情况下,我们可以让爬虫2min爬一次就好了,当然这些都是可以由数据团队来配置维护了, 好了,下面我们用爬虫模拟一下。
复制代码 代码如下:
using System;
using System.Net;
namespace ConsoleApplication2
{
public class Program
{
static void Main(string[] args)
{
DateTime prevDateTime = DateTime.MinValue;
for (int i = 0; i < 10; i++)
{
try
{
var url = "http://cnblogs.com";
var request = (HttpWebRequest)HttpWebRequest.Create(url);
request.Method = "Head";
if (i > 0)
{
request.IfModifiedSince = prevDateTime;
}
request.Timeout = 3000;
var response = (HttpWebResponse)request.GetResponse();
var code = response.StatusCode;
//如果服务器返回状态是200,则认为网页已更新,记得当时的服务器时间
if (code == HttpStatusCode.OK)
{
prevDateTime = Convert.ToDateTime(response.Headers[HttpResponseHeader.Date]);
}
Console.WriteLine("当前服务器的状态码:{0}", code);
}
catch (WebException ex)
{
if (ex.Response != null)
{
var code = (ex.Response as HttpWebResponse).StatusCode;
Console.WriteLine("当前服务器的状态码:{0}", code);
}
}
}
}
}
}
二:网页编码的问题
有时候我们已经抓取到网页了,准备去解析的时候,tmd的全部是乱码,真是操蛋,比如下面这样,
或许我们依稀的记得在html的meta中有一个叫做charset的属性,里面记录的就是编码方式,还有一个要点就是response.CharacterSet这个属性中同样也记录了编码方式,下面我们再来试试看。

居然还是乱码,蛋疼了,这次需要到官网上面去看一看,到底http头信息里面都交互了些什么,凭什么浏览器能正常显示,爬虫爬过来的就不行。
查看了http头信息,终于我们知道了,浏览器说我可以解析gzip,deflate,sdch这三种压缩方式,服务器发送的是gzip压缩,到这里我们也应该知道了常用的web性能优化。
复制代码 代码如下:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading;
using HtmlAgilityPack;
using System.Text.RegularExpressions;
using System.Net;
using System.IO;
using System.IO.Compression;
namespace ConsoleApplication2
{
public class Program
{
static void Main(string[] args)
{
//var currentUrl = "http://www.mm5mm.com/";
var currentUrl = "http://www.sohu.com/";
var request = WebRequest.Create(currentUrl) as HttpWebRequest;
var response = request.GetResponse() as HttpWebResponse;
var encode = string.Empty;
if (response.CharacterSet == "ISO-8859-1")
encode = "gb2312";
else
encode = response.CharacterSet;
Stream stream;
if (response.ContentEncoding.ToLower() == "gzip")
{
stream = new GZipStream(response.GetResponseStream(), CompressionMode.Decompress);
}
else
{
stream = response.GetResponseStream();
}
var sr = new StreamReader(stream, Encoding.GetEncoding(encode));
var html = sr.ReadToEnd();
}
}
}
三:网页解析
既然经过千辛万苦拿到了网页,下一个就要解析了,当然正则匹配是个好方法,毕竟工作量还是比较大的,可能业界也比较推崇 HtmlAgilityPack这个解析工具,能够将Html解析成XML,然后可以用XPath去提取指定的内容,大大提高了开发速度,性能也不赖,毕竟Agility也就是敏捷的意思,关于XPath的内容,大家看懂W3CSchool的这两张图就OK了。
复制代码 代码如下:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading;
using HtmlAgilityPack;
using System.Text.RegularExpressions;
using System.Net;
using System.IO;
using System.IO.Compression;
namespace ConsoleApplication2
{
public class Program
{
static void Main(string[] args)
{
//var currentUrl = "http://www.mm5mm.com/";
var currentUrl = "http://www.sohu.com/";
var request = WebRequest.Create(currentUrl) as HttpWebRequest;
var response = request.GetResponse() as HttpWebResponse;
var encode = string.Empty;
if (response.CharacterSet == "ISO-8859-1")
encode = "gb2312";
else
encode = response.CharacterSet;
Stream stream;
if (response.ContentEncoding.ToLower() == "gzip")
{
stream = new GZipStream(response.GetResponseStream(), CompressionMode.Decompress);
}
else
{
stream = response.GetResponseStream();
}
var sr = new StreamReader(stream, Encoding.GetEncoding(encode));
var html = sr.ReadToEnd();
sr.Close();
HtmlDocument document = new HtmlDocument();
document.LoadHtml(html);
//提取title
var title = document.DocumentNode.SelectSingleNode("//title").InnerText;
//提取keywords
var keywords = document.DocumentNode.SelectSingleNode("//meta[@name='Keywords']").Attributes["content"].Value;
}
}
}
好了,打完收工,睡觉。。。
标签:
抓取,页面
常春岛资源网 Design By www.syssdc.com
广告合作:本站广告合作请联系QQ:858582 申请时备注:广告合作(否则不回)
免责声明:本站文章均来自网站采集或用户投稿,网站不提供任何软件下载或自行开发的软件! 如有用户或公司发现本站内容信息存在侵权行为,请邮件告知! 858582#qq.com
免责声明:本站文章均来自网站采集或用户投稿,网站不提供任何软件下载或自行开发的软件! 如有用户或公司发现本站内容信息存在侵权行为,请邮件告知! 858582#qq.com
常春岛资源网 Design By www.syssdc.com
暂无评论...
《魔兽世界》大逃杀!60人新游玩模式《强袭风暴》3月21日上线
暴雪近日发布了《魔兽世界》10.2.6 更新内容,新游玩模式《强袭风暴》即将于3月21 日在亚服上线,届时玩家将前往阿拉希高地展开一场 60 人大逃杀对战。
艾泽拉斯的冒险者已经征服了艾泽拉斯的大地及遥远的彼岸。他们在对抗世界上最致命的敌人时展现出过人的手腕,并且成功阻止终结宇宙等级的威胁。当他们在为即将于《魔兽世界》资料片《地心之战》中来袭的萨拉塔斯势力做战斗准备时,他们还需要在熟悉的阿拉希高地面对一个全新的敌人──那就是彼此。在《巨龙崛起》10.2.6 更新的《强袭风暴》中,玩家将会进入一个全新的海盗主题大逃杀式限时活动,其中包含极高的风险和史诗级的奖励。
《强袭风暴》不是普通的战场,作为一个独立于主游戏之外的活动,玩家可以用大逃杀的风格来体验《魔兽世界》,不分职业、不分装备(除了你在赛局中捡到的),光是技巧和战略的强弱之分就能决定出谁才是能坚持到最后的赢家。本次活动将会开放单人和双人模式,玩家在加入海盗主题的预赛大厅区域前,可以从强袭风暴角色画面新增好友。游玩游戏将可以累计名望轨迹,《巨龙崛起》和《魔兽世界:巫妖王之怒 经典版》的玩家都可以获得奖励。
更新日志
2025年11月30日
2025年11月30日
- 小骆驼-《草原狼2(蓝光CD)》[原抓WAV+CUE]
- 群星《欢迎来到我身边 电影原声专辑》[320K/MP3][105.02MB]
- 群星《欢迎来到我身边 电影原声专辑》[FLAC/分轨][480.9MB]
- 雷婷《梦里蓝天HQⅡ》 2023头版限量编号低速原抓[WAV+CUE][463M]
- 群星《2024好听新歌42》AI调整音效【WAV分轨】
- 王思雨-《思念陪着鸿雁飞》WAV
- 王思雨《喜马拉雅HQ》头版限量编号[WAV+CUE]
- 李健《无时无刻》[WAV+CUE][590M]
- 陈奕迅《酝酿》[WAV分轨][502M]
- 卓依婷《化蝶》2CD[WAV+CUE][1.1G]
- 群星《吉他王(黑胶CD)》[WAV+CUE]
- 齐秦《穿乐(穿越)》[WAV+CUE]
- 发烧珍品《数位CD音响测试-动向效果(九)》【WAV+CUE】
- 邝美云《邝美云精装歌集》[DSF][1.6G]
- 吕方《爱一回伤一回》[WAV+CUE][454M]